图论
自动化测试
CASE表达式
安卓分区
elk
技术群
Hudi
博通蓝牙使能
增强现实
栈
状态模式
自定义类型
大模型
知识等级分类
舌象
图像视图
webdav
光纤光栅
接口测试
微信官方扫码登录文档
自监督学习
2024/4/11 20:33:21
【无监督】2、MAE | 自监督模型提取的图像特征也很能打!(CVPR2022 Oral)
文章目录 一、背景二、方法三、效果 论文:Masked Autoencoders Are Scalable Vision Learners
代码:https://github.com/facebookresearch/mae
出处:CVPR2022 Oral | 何凯明 | FAIR
一、背景
本文的标题突出了两个词:
masked…
Hi-TRS:骨架点视频序列的层级式建模及层级式自监督学习
论文题目:Hierarchically Self-Supervised Transformer for Human Skeleton Representation Learning
论文下载地址:https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136860181.pdf
代码地址:https://github.com/yuxiaochen1103…
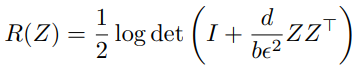
浅谈 EMP-SSL + 代码解读:自监督对比学习的一种极简主义风
论文链接:https://arxiv.org/pdf/2304.03977.pdf
代码:https://github.com/tsb0601/EMP-SSL
其他学习链接:突破自监督学习效率极限!马毅、LeCun联合发布EMP-SSL:无需花哨trick,30个epoch即可实现SOTA 主要…

论文阅读:Cross and Learn: Cross-Modal Self-supervision
目录
Contributions
Method
Cross-Modal Loss
Diversity Loss
Combining Both Loss Contributions
Results 论文名称:Cross and Learn: Cross-Modal Self-supervision(2018 GCPR: German Conference on Pattern Recognition)
论文作者…

论文阅读:Generating Videos with Scene Dynamics
目录
Contributions
Method
1、Video Generator Network
2、Video Discriminator Network
Results
1、Quantitative Results on Video Generator
2、Video Representation Learning (Video Discriminator) 论文名称:Generating Videos with Scene Dynamics&a…

论文阅读:Self-Supervised Video Representation Learning With Odd-One-Out Networks
目录
Contributions
Method
1、Model
2、Three sampling strategies.
3、Video frame encoding.
Results
More Reference to Follow 论文名称:Self-Supervised Video Representation Learning With Odd-One-Out Networks(2017 CVPR)
…
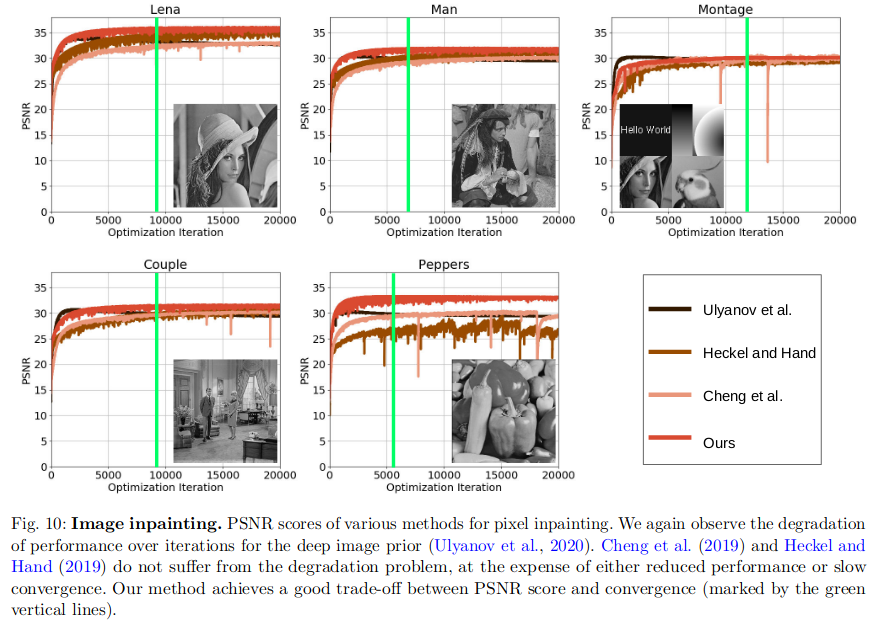
DIP: Spectral Bias of DIP 频谱偏置解释DIP
On Measuring and Controlling the Spectral Bias of the Deep Image Prior 文章目录 On Measuring and Controlling the Spectral Bias of the Deep Image Prior1. 方法原理1.1 动机1.2 相关概念1.3 方法原理频带一致度量与网络退化谱偏移和网络结构的关系Lipschitz-controlle…

NLP 自古以来的各预训练模型 (PTMs) 和预训练任务小结
😄目前写了预训练模型与任务的大致分类,还未将具体原理总结。持续更新ing。 ⏰ 早期的PTMs在模型结构上做的尝试比较多,transformers出现后,研究者们研究的重点就从模型结构转移到了训练任务与策略上。 ⭐ PTMSs优势在于: 1、大量的无标注数据进行预训练,降低人工标注成…

PixMIM论文笔记
论文名称:PixMIM: Rethinking Pixel Reconstruction in Masked Image Modeling 发表时间:2023 年 3 月 4 日 作者及组织:上海人工智能实验室、西蒙菲莎大学、香港中文大学 GitHub:https://github.com/open-mmlab/mmselfsup/tree/d…
简单谈谈 EMP-SSL:自监督对比学习的一种极简主义风
论文链接:https://arxiv.org/pdf/2304.03977.pdf
代码:https://github.com/tsb0601/EMP-SSL
其他学习链接:突破自监督学习效率极限!马毅、LeCun联合发布EMP-SSL:无需花哨trick,30个epoch即可实现SOTA 主要…

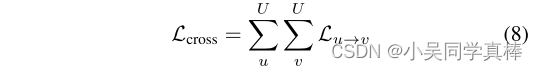
【论文阅读笔记】(2021 CVPR)3D Human Action Representation Learning via Cross-View Consistency Pursuit
写在前面
方法部分好多公式变量,编辑器再打一遍好麻烦。。。偷个懒,就直接把这部分的笔记导出成图片咯,并且我按我自己理解比较顺的逻辑重新捋了一下。 3D Human Action Representation Learning via Cross-View Consistency Pursuit
&…

【论文阅读笔记】(2022 ECCV)Contrastive Positive Mining for Unsupervised 3D Action Representation Learning
论文题目:Contrastive Positive Mining for Unsupervised 3D Action Representation Learning
论文下载地址:https://arxiv.org/pdf/2208.03497.pdf 目录
0. 论文简介 & 创新点
1、Contrastive Positive Mining (CPM)
2、Similarity Distributio…

论文阅读:Self-supervised spatio-temporal representation learning for videos by predicting motion and app
目录
Contributions
Method
1、Partitioning patterns
2、Motion Statistics
3、Appearance Statistics
Results 论文标题:Self-supervised spatio-temporal representation learning for videos by predicting motion and appearance statistics(…

论文阅读:Self-supervised video representation learning with space-time cubic puzzles
论文名称:Self-supervised video representation learning with space-time cubic puzzles(2019 AAAI)
论文作者:Dahun Kim, Donghyeon Cho, In So Kweon
下载地址:https://ojs.aaai.org/index.php/AAAI/article/vie…

论文阅读:Colorful Image Colorization
目录
Contributions
Method
1、Objective Function
2、Class rebalancing
3、Class Probabilities to Point Estimates
Code
Results
1、Colorization results on 10k images in the ImageNet validation set
2、Colorization Turing Test.
3、Cross-Channel Encodin…
论文阅读以及复现:Shuffle and learn: Unsupervised learning using temporal order verification
目录
Summary
Details
1、Frame Sampling Strategy
2、Training & Testing
2.1 Training Details
2.1 Testing Details (Details for Action Recognition)
复现过程中遇到的问题 论文名称:Shuffle and learn: Unsupervised learning using tempora…
【学习笔记】元学习如何解决计算机视觉少样本学习的问题?
目录
1 计算机视觉少样本学习
2 元学习
3 寻找最优初始参数值方法:MAML
3.1 算法步骤
3.2 代码:使用MAML 和 FO-MAML、任务增强完成Few-shot Classification
4 距离度量方法:Siamese Network,ProtoNet,RN
4.1 孪生网络(Sia…

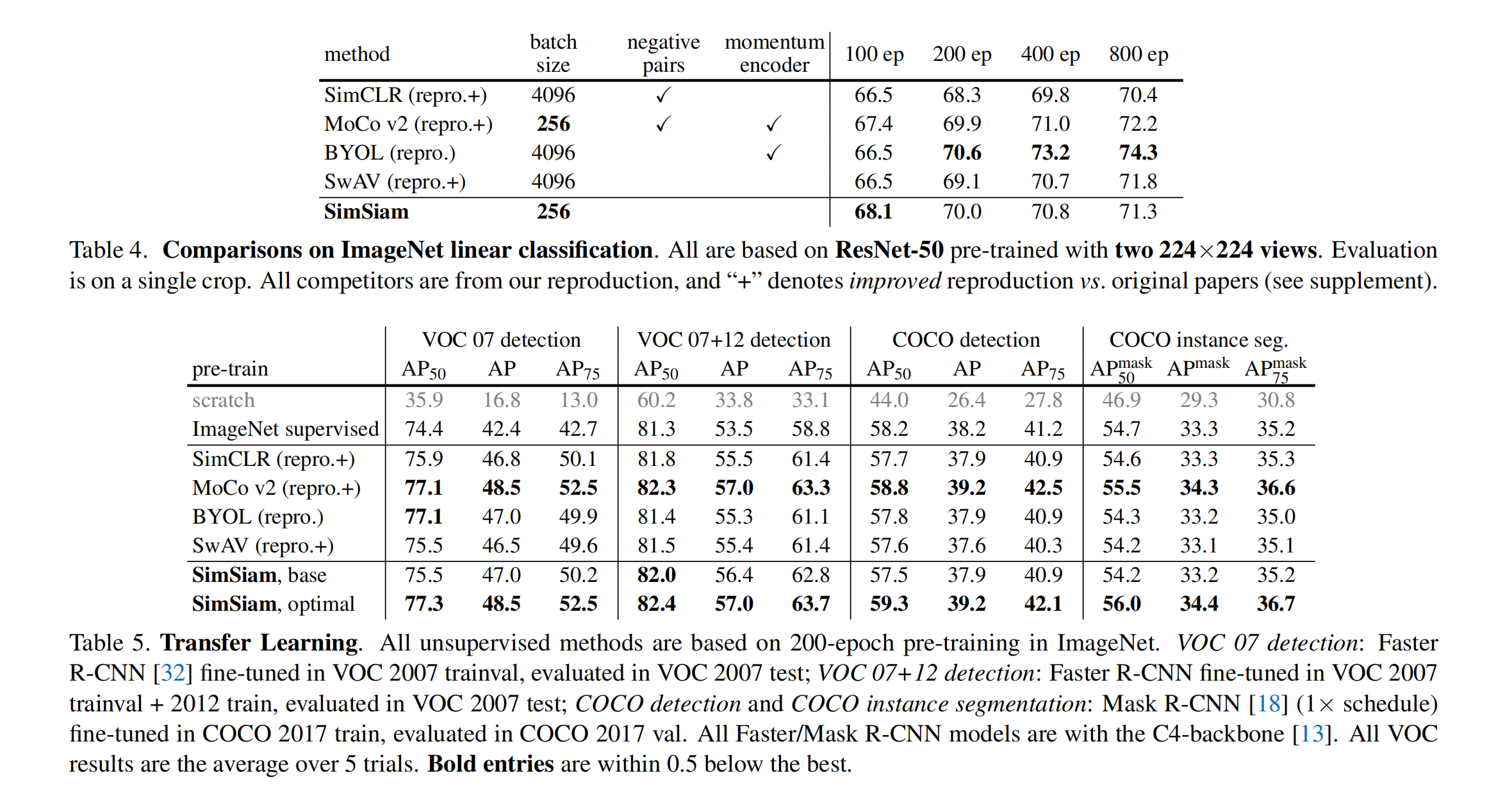
【无监督】6、SimSiam | 基于孪生网络的对比学习的成功源于梯度截断!
文章目录 一、背景二、方法三、效果 论文:Exploring Simple Siamese Representation Learning
出处:FAIR | 何恺明大佬
本文作者抛出了两个爆炸💥性结论: 结论一:基于孪生网络的对比的学习的成功,不源于 …

Data2Vec:视觉、语音和语言的语境化目标表征的高效自监督学习
Efficient Self-supervised Learning with Contextualized Target Representations for Vision, Speech and Language
(视觉、语音和语言的语境化目标表征的高效自监督学习) 论文:efficient-self-supervised-learning-with-contextualized-t…
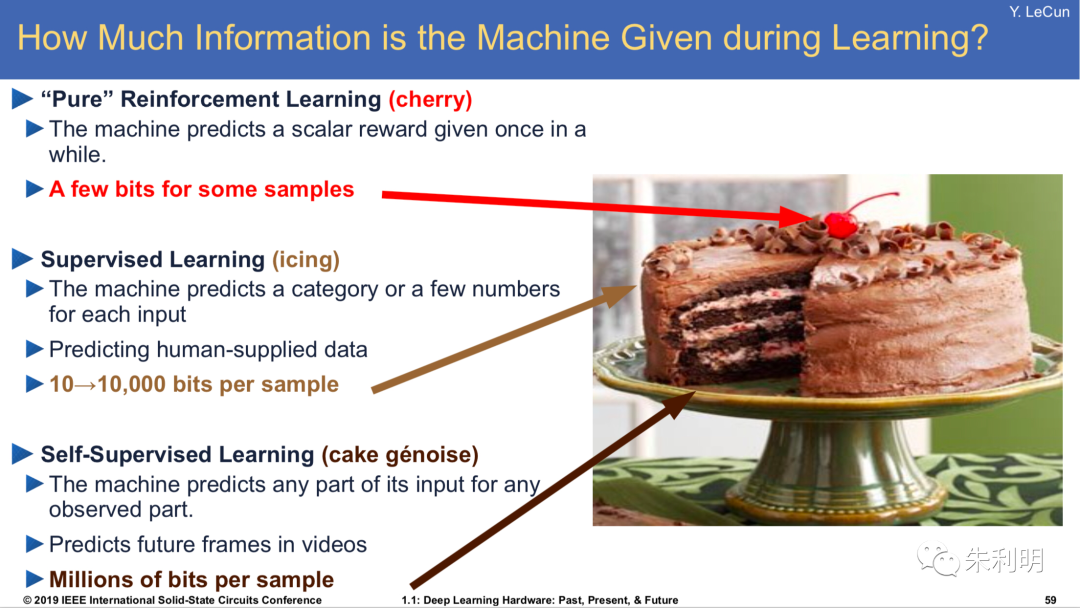
人工智能的奥秘:机器学习的各大门派
本篇文章是博主在人工智能等领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对人工智能等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。 文章分类在学习摘录和笔记专…

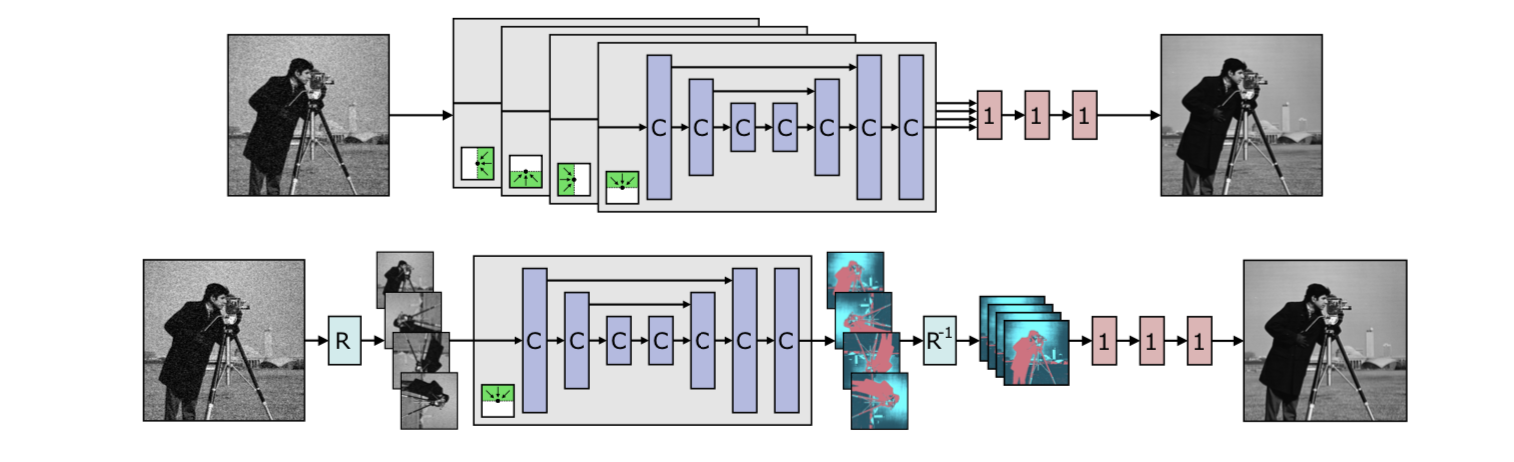
Deep Image Prior:《Deep Image Prior》经典文献阅读总结与实现
文章目录 Deep Image Prior1. 方法原理1.1 研究动机1.2 方法 2. 实验验证2.1 去噪2.2 超分辨率2.3 图像修复2.4 消融实验 3. 总结 Deep Image Prior
1. 方法原理 1.1 研究动机
动机
深度神经网络在图像复原和生成领域有非常好的表现一般归功于神经网络学习到了图像的先验信息…
计算机视觉 + Self-Supervised Learning 五种算法原理解析
计算机视觉领域下自监督学习方法原理 导语为什么在计算机视觉领域中进行自我监督学习? 自监督学习方法Generative methodsBEiT 架构 Predictive methodsContrastive methodsBootstraping methodsSimply Extra Regularization methods 导语
自监督学习是一种机器学习…

【图神经网络 · 科研笔记5】异构信息网络,利用注意力选择元路径;利用进化邻域和社群实现自监督动态图嵌入,交叉监督对比学习;近期科研思维导图小汇总;
记录部分科研文献阅读相关内容【划重点】,主题“图神经网络”,仅学习使用。 🎯作者主页: 追光者♂🔥 🌸个人简介: 📝[1] CSDN 博客专家📝 🏆[2] 人工智能领域优质创作者🏆 🌟[3] 2023年城市之星领跑者TOP1(哈尔滨)🌿 🌿[4] 2022年度…
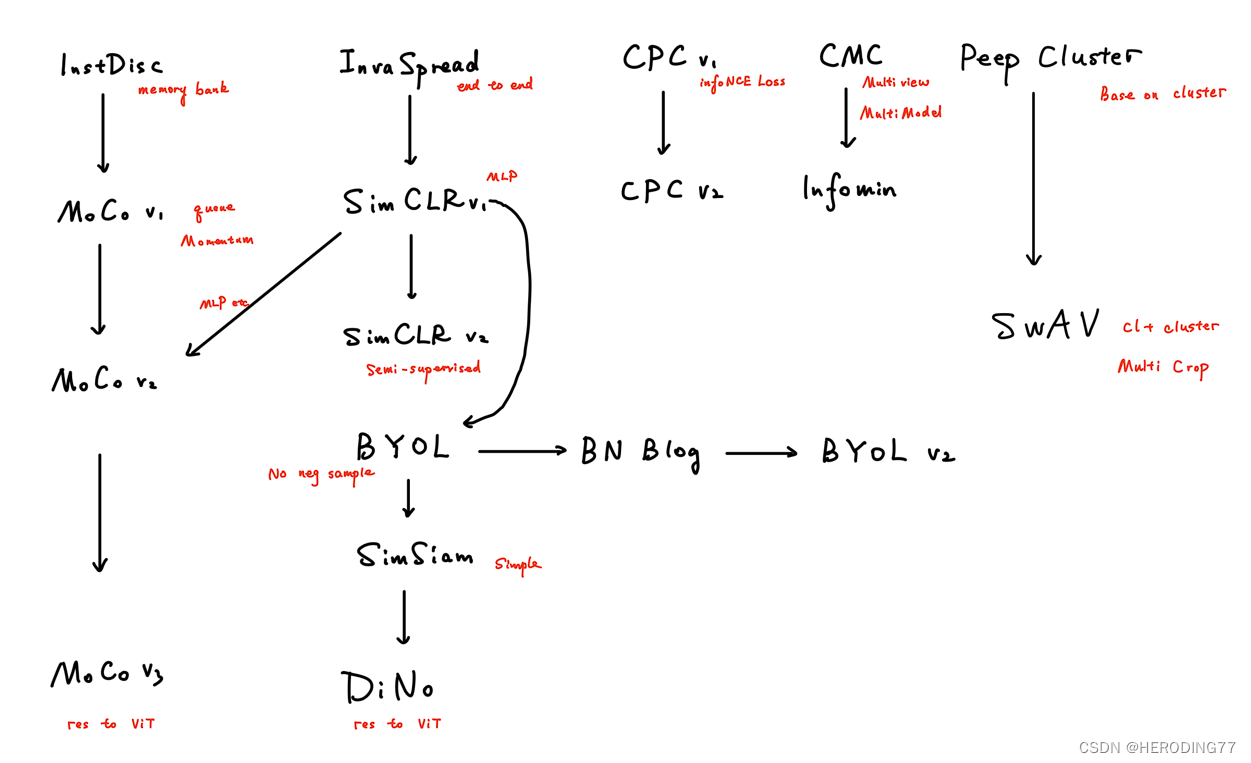
【学习笔记】计算机视觉对比学习综述
计算机视觉对比学习综述 前言百花齐放InstDiscInvaSpreadCPCCMC CV双雄MoCoSimCLRMoCo v2SimCLR v2SwAV 不用负样本BYOLSimSiam TransformerMoCo v3DINO 总结参考链接 前言
本篇对比学习综述内容来自于沐神对比学习串讲视频以及其中所提到的论文和博客,对应的链接详…

深度学习|自监督学习、MAE学习策略、消融实验
前言:最近在阅读论文,发现太多机器学习的知识不懂,把最近看的一篇论文有关的知识点汇总了一下。 自监督学习、MAE学习策略、消融实验 自监督学习MAE学习策略消融实验 自监督学习
Pretrain-Finetune(预训练精调)模式&…

【论文解读】SiamMAE:用于从视频中学习视觉对应关系的 MAE 简单扩展
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://siam-mae-video.github.io/resources/paper.pdf
项目主页:https://siam-mae-video.github.io/
1.背景
时间是视觉学习背景下的一个特殊维度,它提供了一…

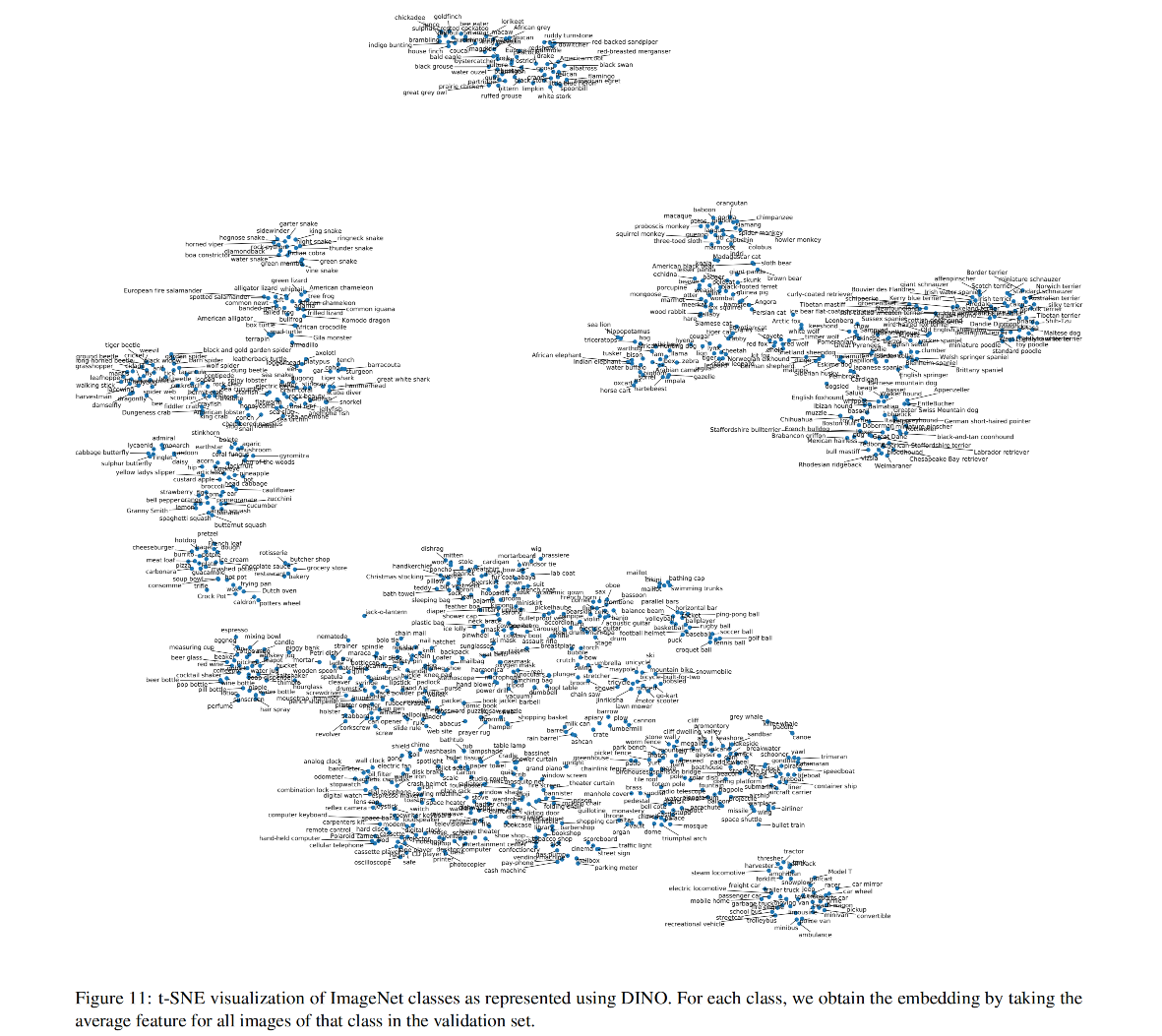
自监督DINO论文笔记
论文名称:Emerging Properties in Self-Supervised Vision Transformers 发表时间:CVPR2021 作者及组织: Facebook AI Research GitHub:https://github.com/facebookresearch/dino/tree/main
问题与贡献
作者认为self-supervise…
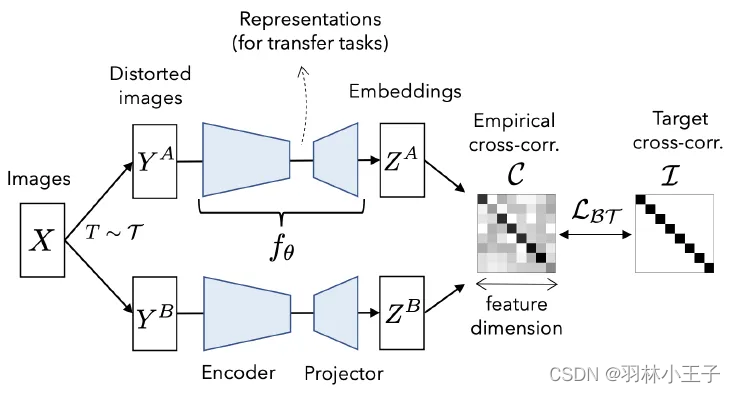
【无监督】5、DINO | 使用自蒸馏和 transformer 来释放自监督学习的超能力(ICCV2021)
文章目录 一、背景二、相关工作三、方法四、效果 论文:Emerging Properties in Self-Supervised Vision Transformers
代码:https://github.com/facebookresearch/dino
出处:ICCV2021 | FAIR
DINO: self-DIstillation with NO …

论文阅读:Unsupervised Representation Learning by Sorting Sequences
目录
Summary
Details
1、Task
2、The proposed Order Prediction Network(OPN)
3、Data sampling strategies
4、Ablation analysis
Trick 1
Trick 2
Trick 3
想法 & 思考 论文名称:Unsupervised Representation Learning by …
无/自监督去噪(1)——一个变迁:N2N→N2V→HQ-SSL
目录 1. 前沿2. N2N3. N2V——盲点网络(BSNs,Blind Spot Networks)开创者3.1. N2V实际是如何训练的? 4. HQ-SSL——认为N2V效率不够高4.1. HQ-SSL的理论架构4.1.1. 对卷积的改进4.1.2. 对下采样的改进4.1.3. 比N2V好在哪ÿ…

Talk | 牛津大学博士后研究员边佳旺:SC-DepthV3-动态场景中的自监督单目深度估计
本期为TechBeat人工智能社区第550期线上Talk。 北京时间11月23日(周四)20:00,牛津大学博士后研究员—边佳旺的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “SC-DepthV3:动态场景中的自监督单目深度估计”,介绍…

【自监督学习】对比学习(Contrastive Learning)介绍
1. 前言
1.1. 为什么要进行自监督学习 我们知道,标注数据总是有限的,就算ImageNet已经很大,但是很难更大,那么它的天花板就摆在那,就是有限的数据总量。NLP领域目前的经验应该是:自监督预训练使用的数据量…
DIP:《Deep Image Prior》经典文献阅读总结与实现
文章目录 Deep Image Prior1. 方法原理1.1 研究动机1.2 方法 2. 实验验证2.1 去噪2.2 超分辨率2.3 图像修复2.4 消融实验 3. 总结 Deep Image Prior
1. 方法原理 1.1 研究动机
动机
深度神经网络在图像复原和生成领域有非常好的表现一般归功于神经网络学习到了图像的先验信息…
⑥【自监督学习 · 时空图神经网络 · 文献精读】知识图谱 | 推荐 | 命名实体识别NER | 空间-时间知识图谱 | 时空知识图 | 时空相似性
后来,月亮说,其实你小时候我真的有跟着你走了很久很久… 🎯作者主页: 追光者♂🔥 🌸个人简介: 💖[1] 计算机专业硕士研究生💖 🌟[2] 2022年度博客之星人工智能领域TOP4🌟 🏅[3] 阿里云社区特邀专家博主🏅 🏆[4] CSDN-人工智能领域优质…
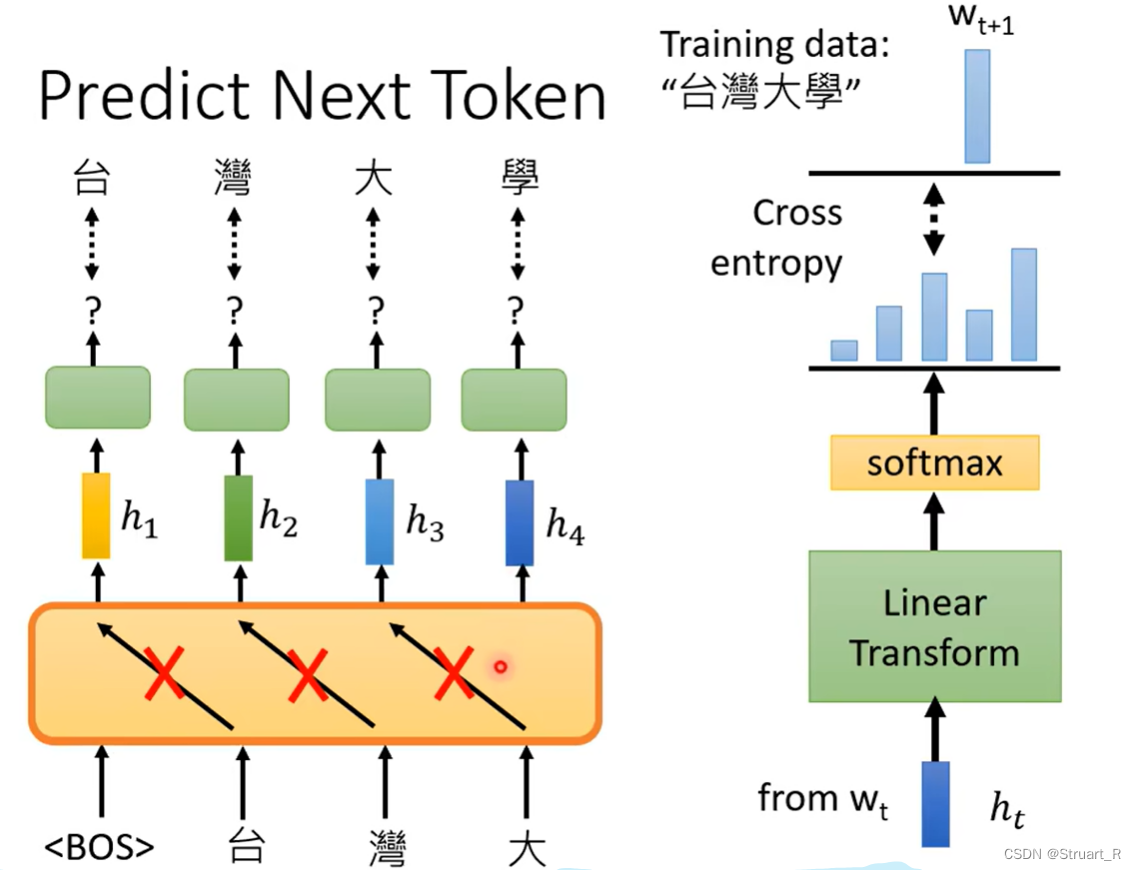
NLP(4)--BERT
目录
一、自监督学习
二、BERT的两个问题
三、GLUE
四、BERT与Transformer的关系
五、BERT的训练方式
六、BERT的四个例子
1、语句分类(情感分析)
2、词性标注
3、立场分析
4、问答系统
七、BERT的后续
1、为什么预训练后的微调可以满足多…